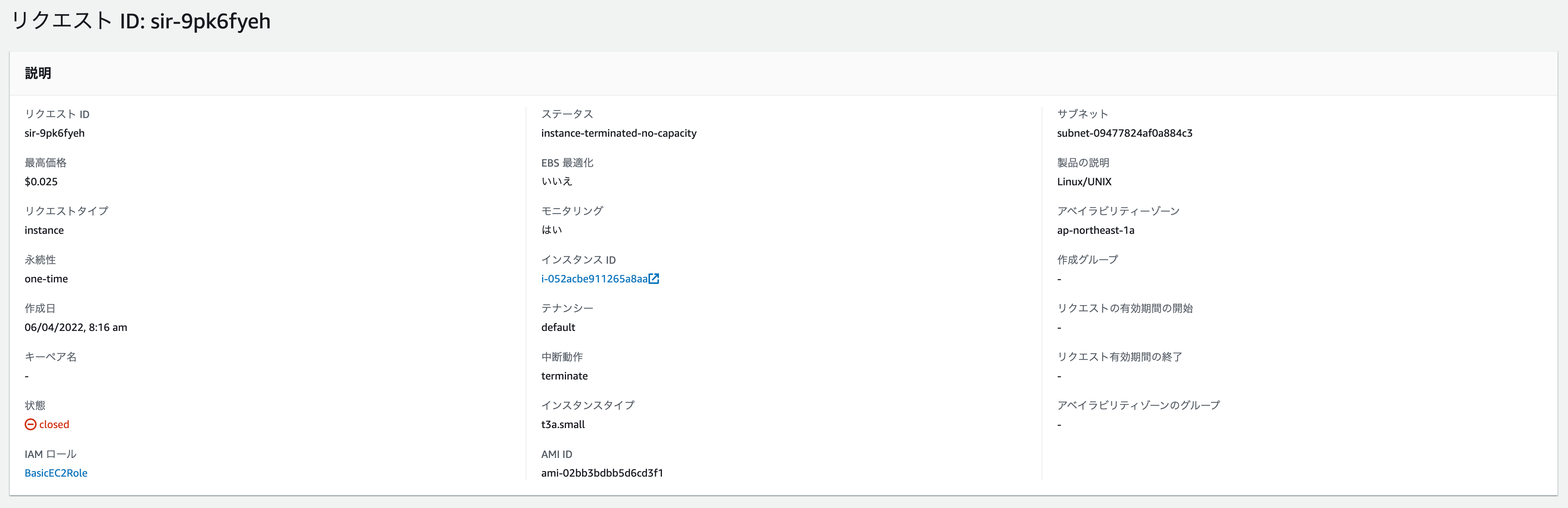
普段はお仕事で Rocket.Chat を利用しているわけですが、基本的にはスポットインスタンスを利用しています。
スポットインスタンスである以上は避けられないのがスポットインスタンスの中断なわけでして、スポットインスタンスの料金履歴を見ながら比較的料金が安定しているインスタンスタイプとアベイラビリティゾーンを選んでいたわけです。
それでも起きるときには起きるものです。久しぶりにインタラプトが発生してスポットインスタンスが逝きました。
中のデータ?
もちろん、一緒に逝きました。バッドプラクティスを実現していた結果です。
これでは良くない。ということで、きちんと対策を取っていきます。(この記事は大作でもあります。)
スポットインスタンスの中断への対応としては、次に挙げられる方法が考えられます。
- EC2 インスタンスをステートレスにするためデータをインスタンス外に保存する
- 中断通知を受けてデータのバックアップをおこなう
1. の手段は、常に利用するわけではなく最大で3日程度までの起動である要件から、今回の場合は Too Much です。
ということで、2. の手段で中断通知を受けてバックアップをおこない、復旧起動させるときにユーザーデータでバックアップをリストアさせる方向で考えます。
スポットインスタンスの中断通知
スポットインスタンスで起動されたインスタンスが何らかの理由により中断されるとき、その2分前に中断通知が届きます。
受け取る方法としては、2つの方法があります。
- EC2 インスタンスメタデータを定期的にチェックして中断通知が入ってくるかを確認する
- EventBridge で受け取る
今回は、EventBridge を利用して中断通知を受け取り、Lambda から Run Command でバックアップスクリプトを実行させると同時に、ChatBot と連携した Slack に通知を行う。方法でいきます。
MongoDB のバックアップ
Rocket.Chat は、内部的にデータベースとして MongoDB が採用されています。通常の MongoDB のダンプコマンドツールとリストアコマンドツールで復元できそうなので、まずはバックアップを行うためのスクリプトを用意します。
手順としては以下の通り。
- Rocket.Chat のサービス停止
- mongodump コマンドでデータベースのダンプ作成
- Zip で固めて S3 にアップロード
データベースバックアップスクリプトを用意する
mongodump コマンドを使ってバックアップすればいいので楽ちんです。
S3 バケットの準備
S3 バケットを適当なバケット名で作成し、バケットポリシーで EC2 インスタンスに割り当てたロールからの PutObject と GetObject を許可します。
スクリプトのテスト
きちんとスクリプトが動作すれば、S3 バケットに rocket-chat-dump.zip がアップロードされています。
中断通知を受け取る
EventBridge から直接 Systems Manager の Run Command を実行させるアクションを定義できますが、どうにもインスタンスの指定がうまく行かず・・・。Lambda の中から Run Command 実行させます。
Lambda 関数の用意
Lambda の中で行うことは、Systems Manager のクライアントオブジェクトを利用して SendCommand API を呼び出すだけです。
このとき、コマンドは非同期で実行されているので処理結果を待つために Waiter を利用して待っています。
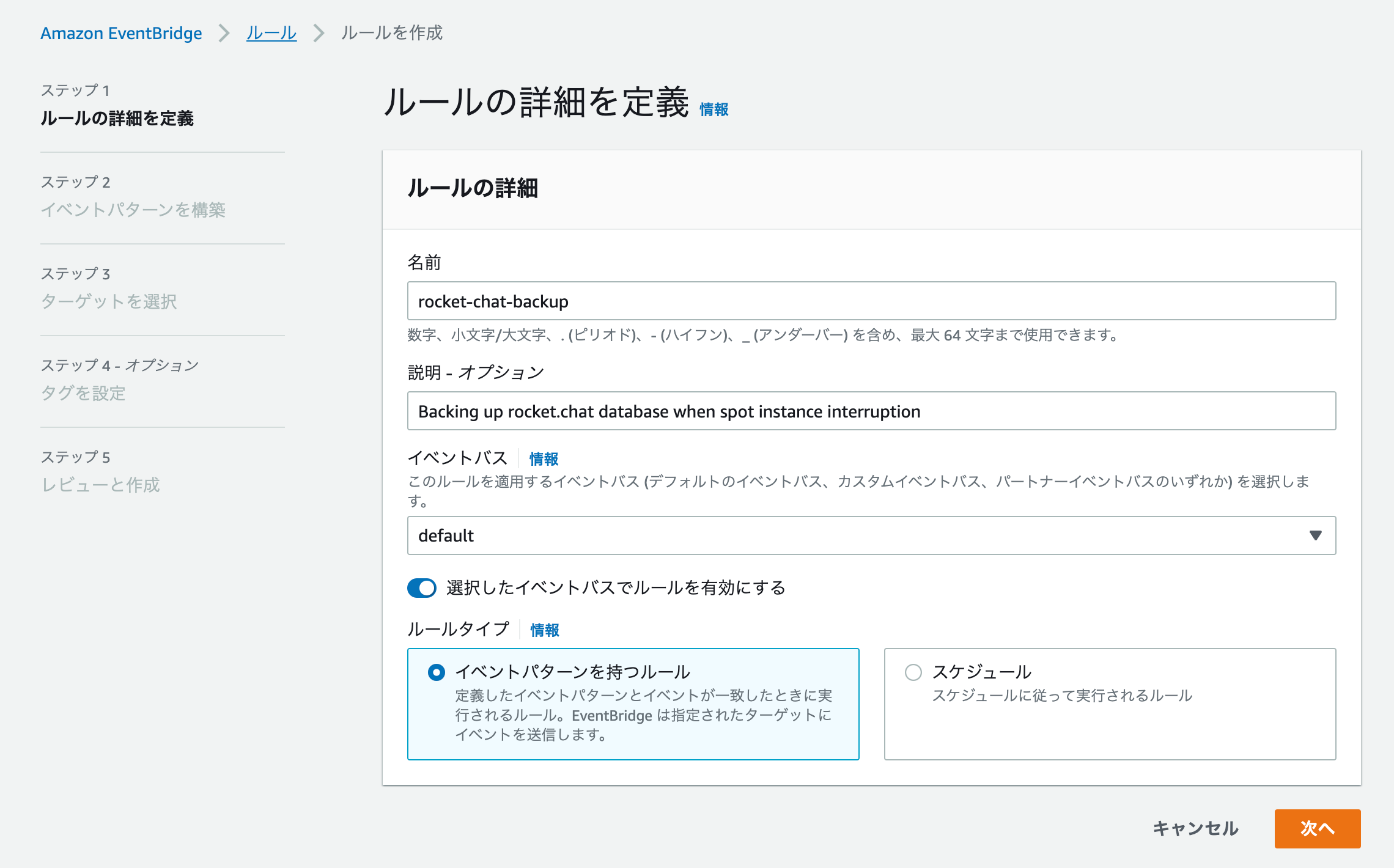
EventBridge で中断通知を受けつけるルールを作成する
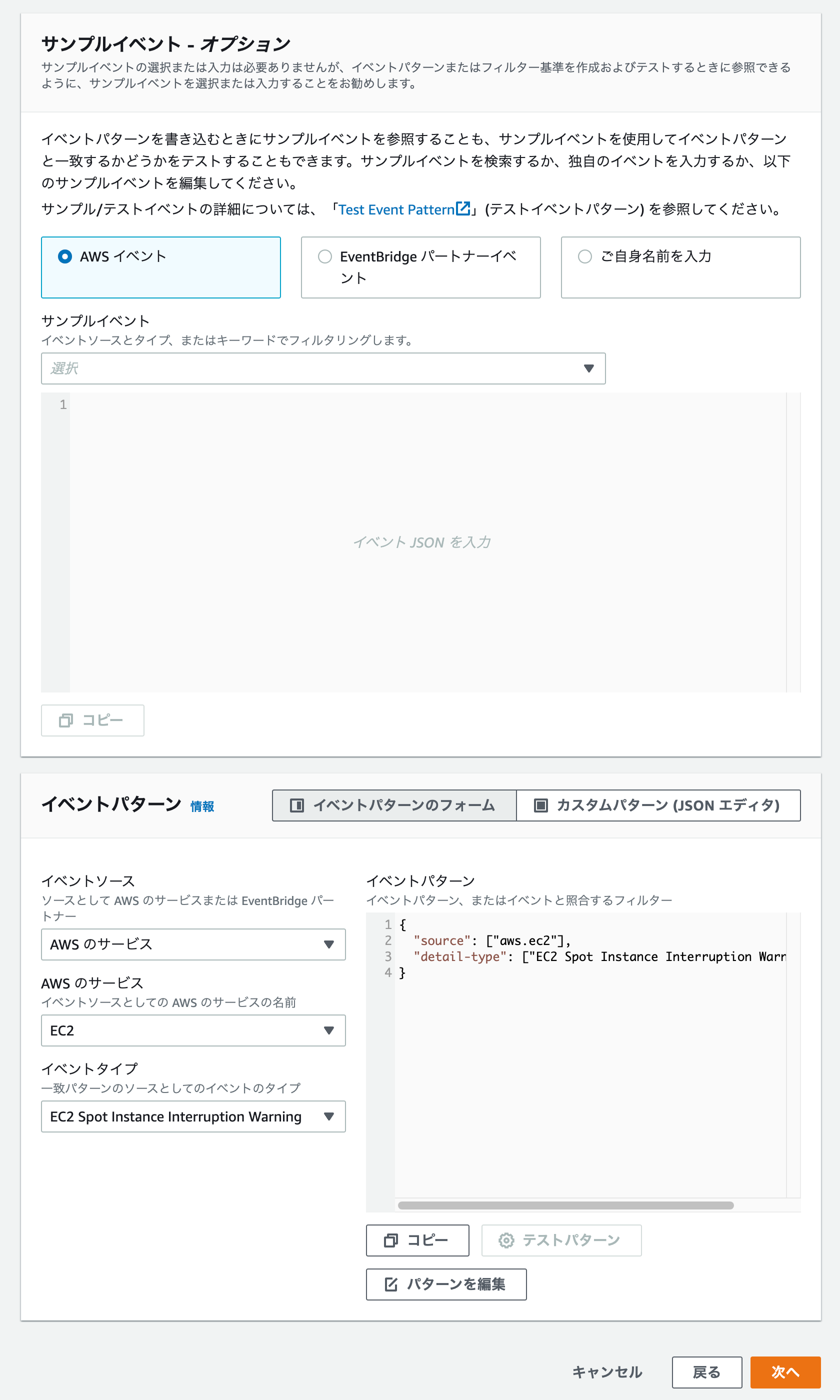
イベントパターンとして、「EC2 Spot Instance Interruption Warning」 を指定します。
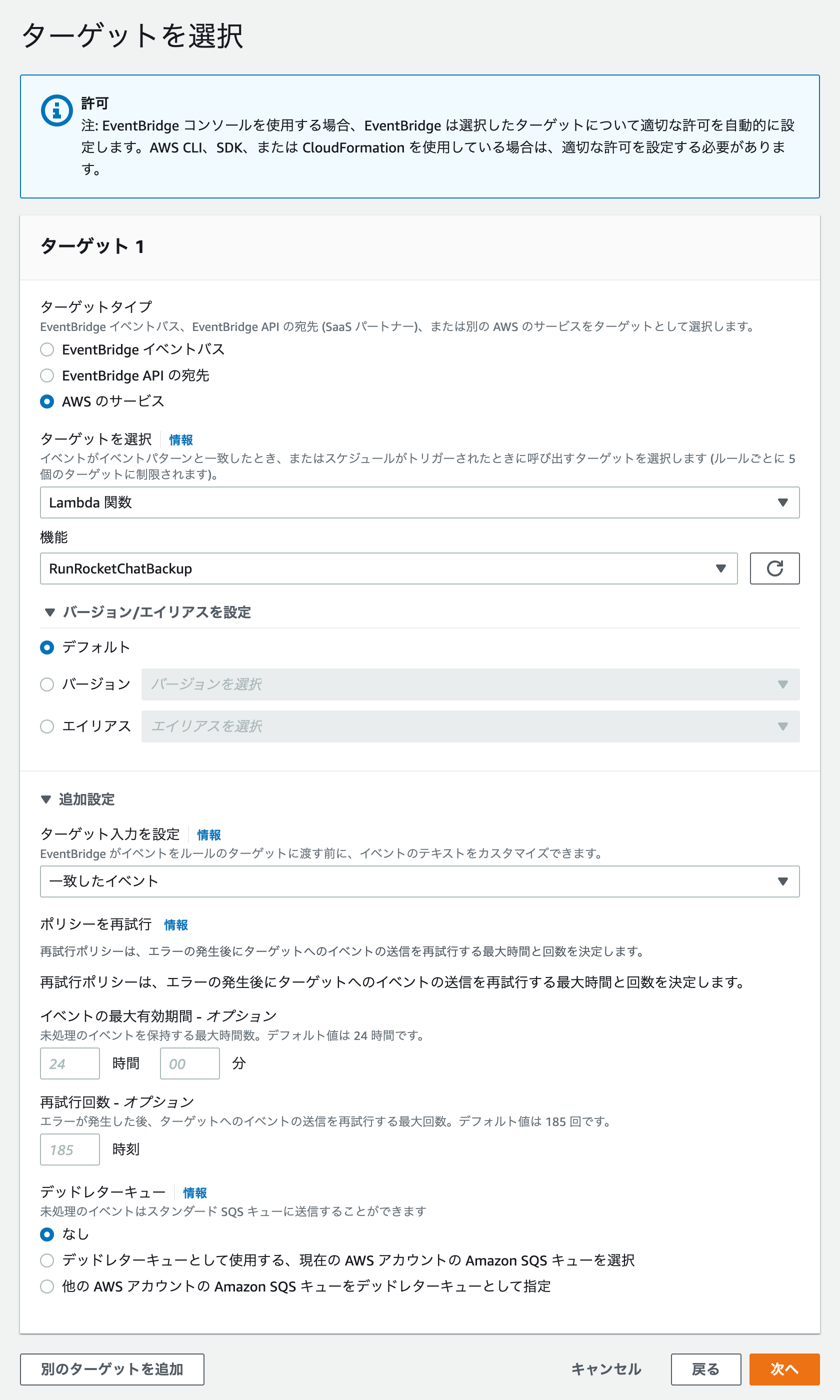
1つ目のターゲットとして先ほど作成した Lambda 関数を指定します。これで、バックアップスクリプトを実行させます。
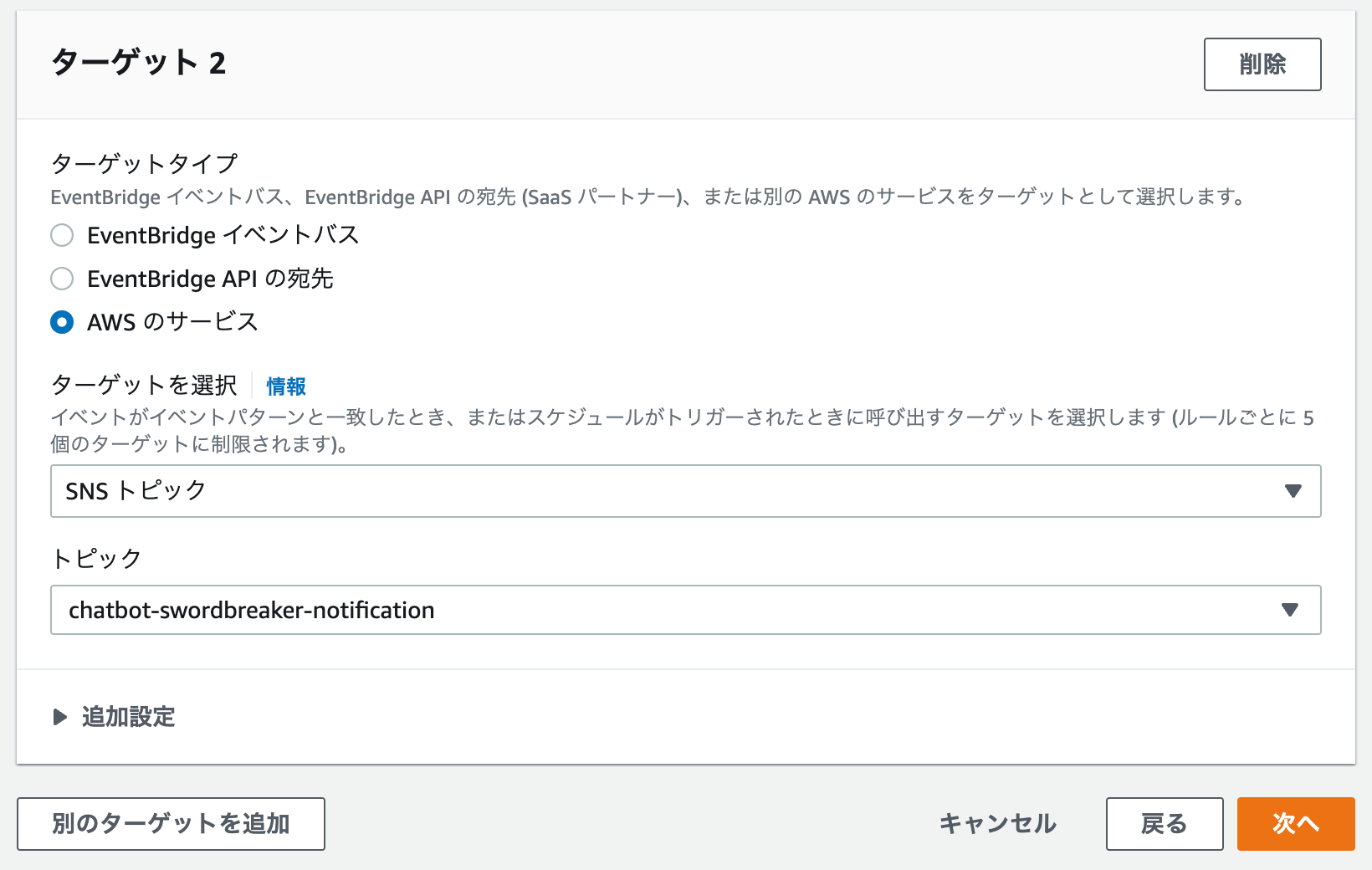
2つ目のターゲットとして、SNS 経由で ChatBot から Slack に通知を送ります。
中断通知を試験する
スポットインスタンスの中断通知はこれまで気軽に試験がやりにくいもののひとつでしたが、AWS Fault Injection Simulator が中断通知を起こすことができるので気軽(?)に試験できるようになりました。
AWS Fault Injection Simulator とは
カオスエンジニアリングのなかで、実際に環境に障害(EC2 インスタンスを止めたり、今回のようにスポットインスタンスの中断させたり)を意図的に発生させて対障害性や回復性に対する試験を行うことができるサービスです。
実験テンプレートを用意することで、任意のタイミングで実験を開始できます。
AWS Fault Injection Simulator で中断通知実験を用意する
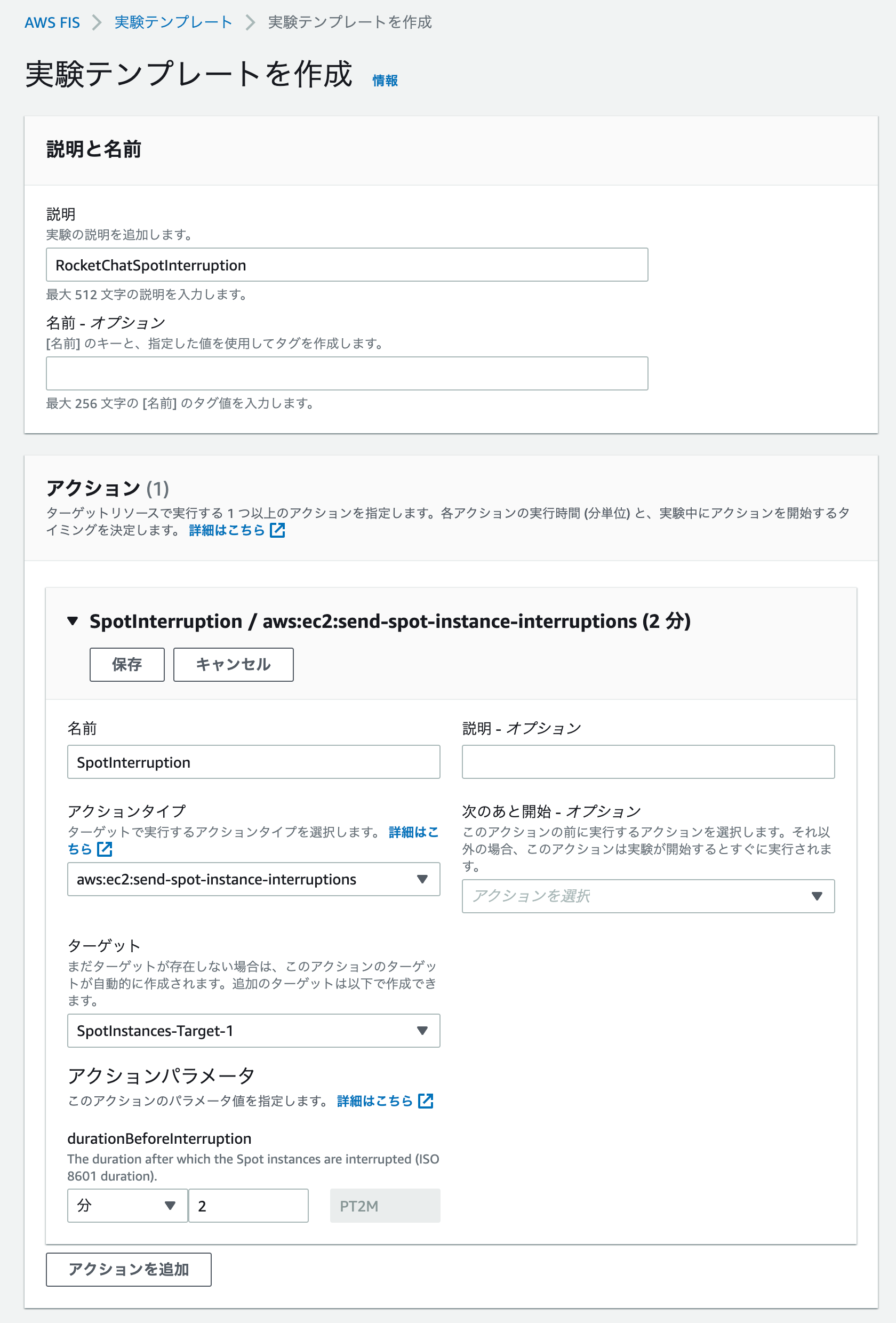
アクションとして「aws:ec2:send-spot-instance-interruptions」を指定します。
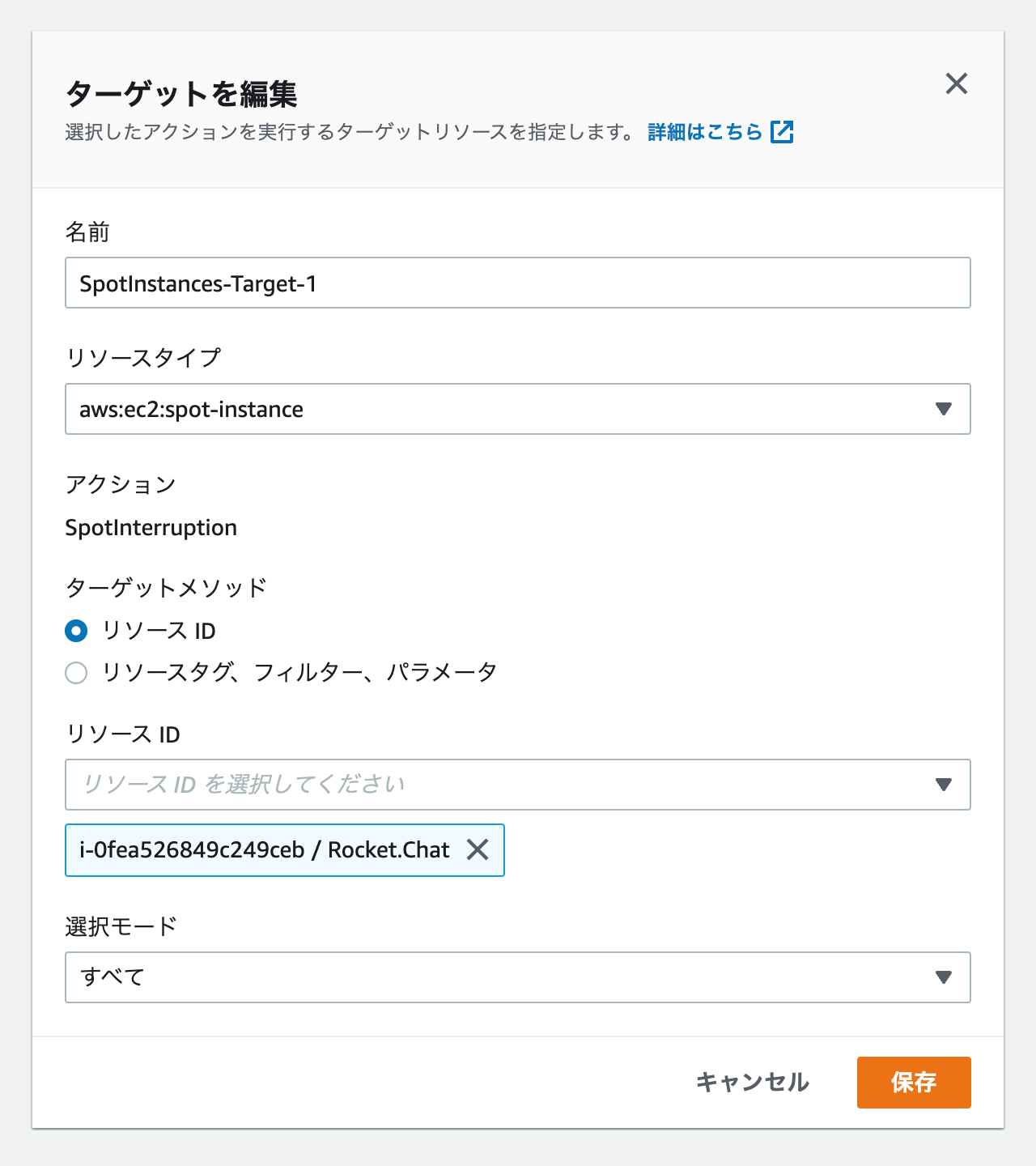
ターゲットとして、先に起動しておいた Rocket.Chat インスタンス(スポットインスタンス)を選択します。
 残りはデフォルトのままで。
残りはデフォルトのままで。
サービスアクセスロールを自動作成させると、アクションの実行に必要な定義が含まれる IAM ロールを作ってくれました。
中断通知を試験する
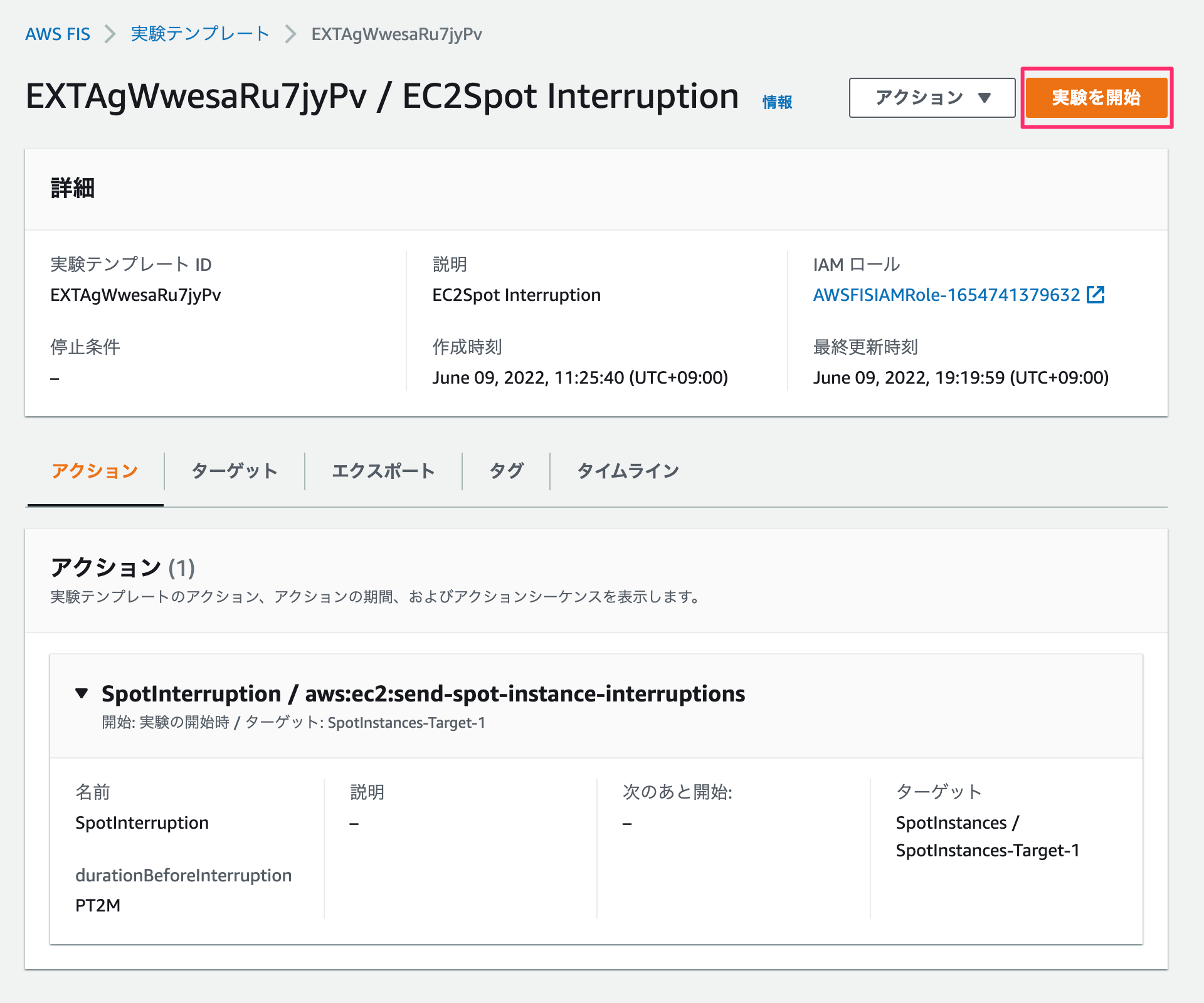
「実験を開始」をクリックすると実験を開始してもよいかの確認がでてきます。
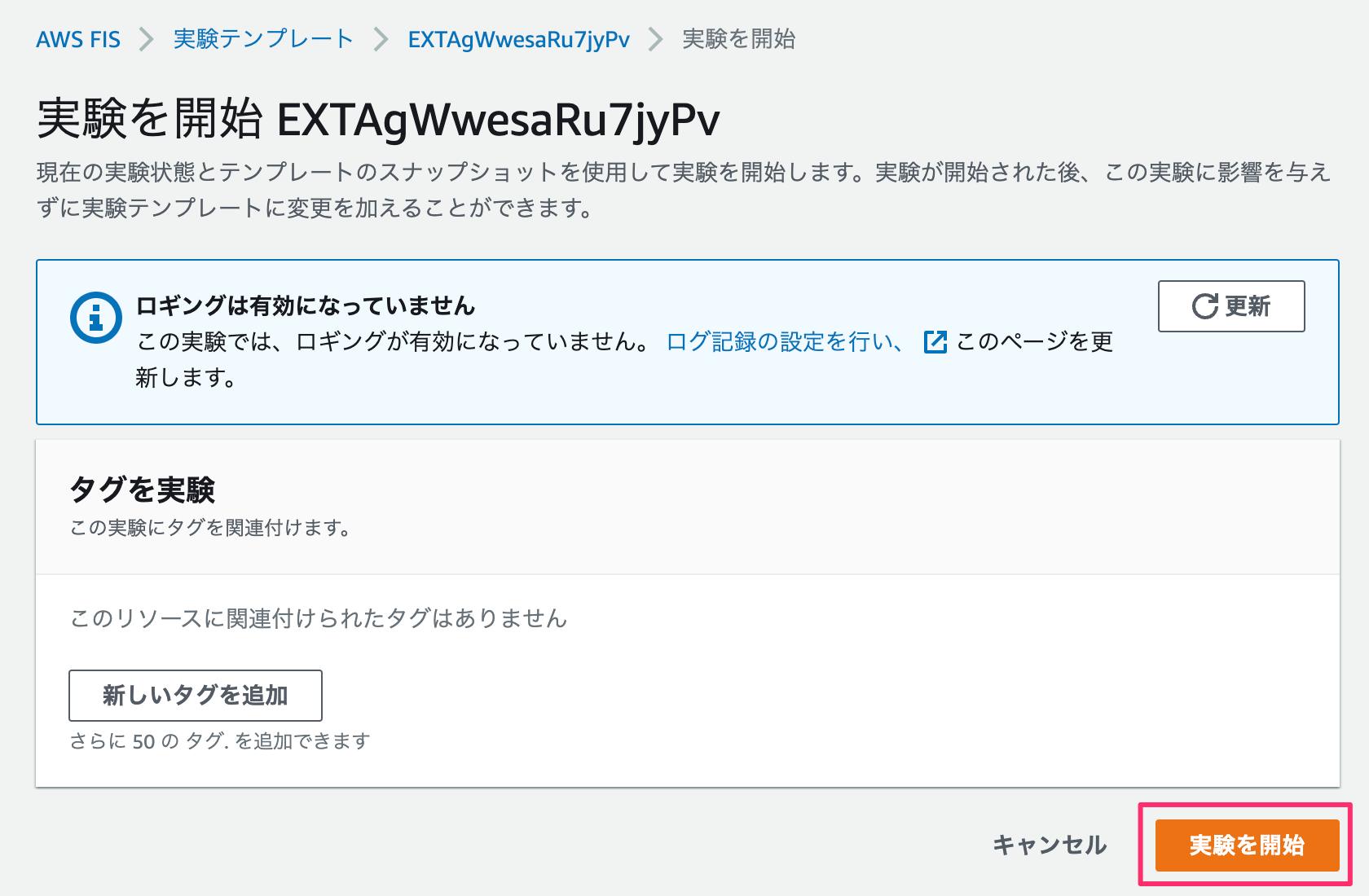
確認画面で「実験を開始」をクリックすると試験が開始されます。今回はログを取ってませんけど必要に応じて取っておくと良いですね。
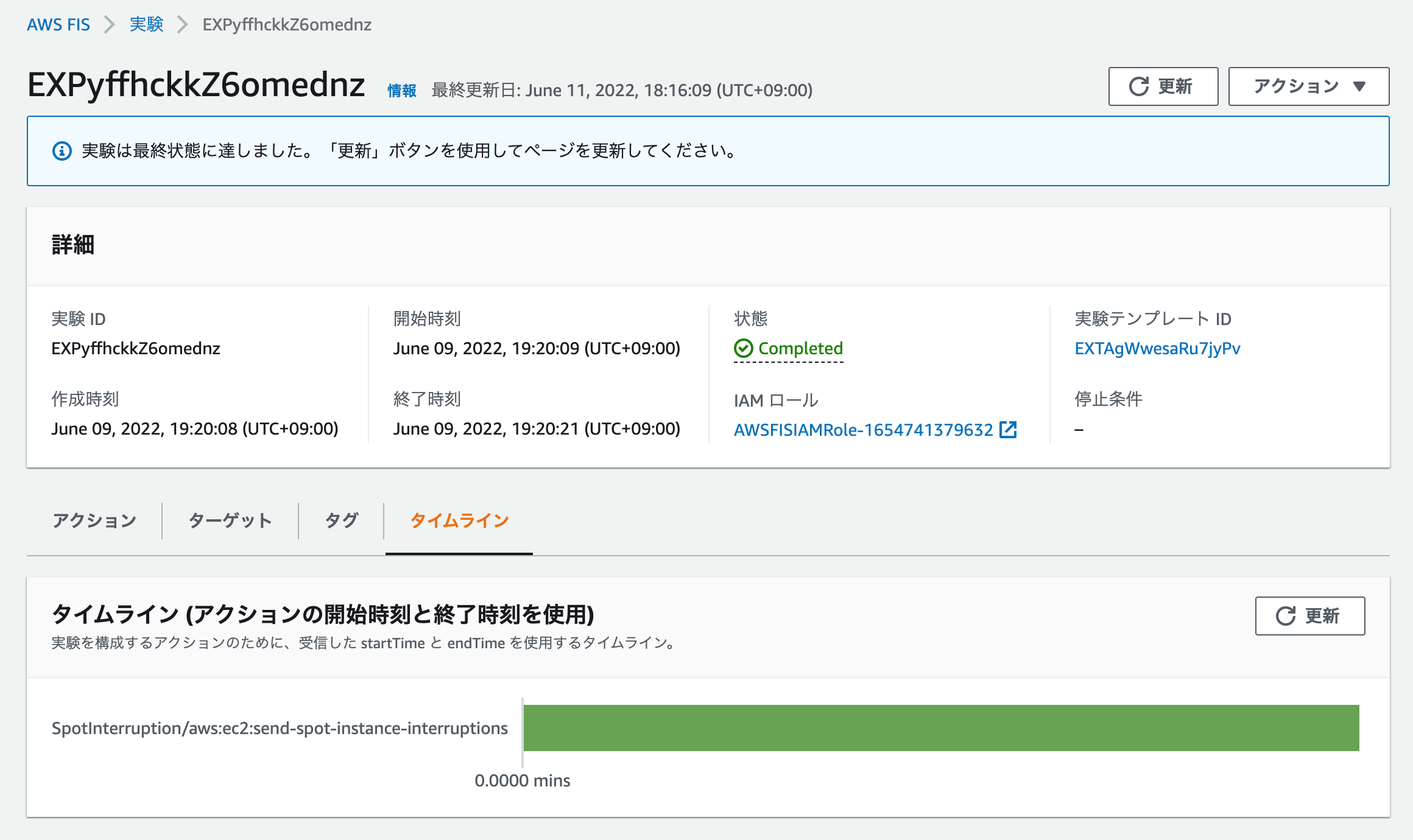
しばらくすると結果が表示されます。タイムラインではアクションごとの実行時間とか見られるようです。
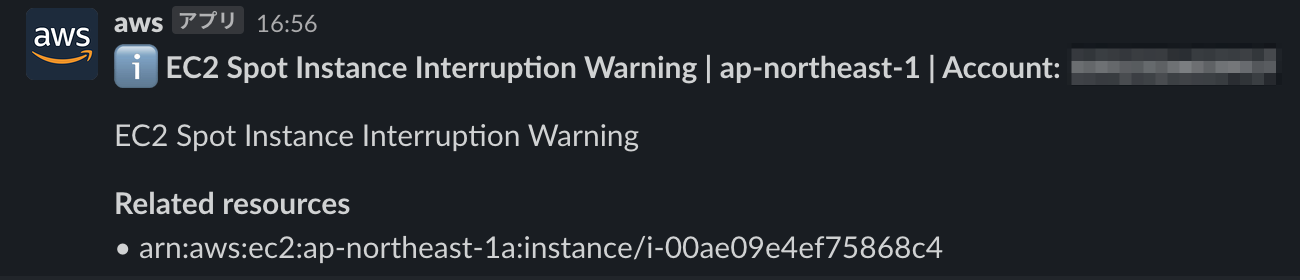
試験が成功すると、スポットインスタンスが実際に終了されます。そして、中断通知イベントが処理されて S3 バケットにバックアップファイルが作成され、Slack に通知が届きます。これで成功です。
ユーザーデータでリストアする
中断通知を受け付けて MongoDB のバックアップを S3 にアップロードすることができるようになりました。2分間もあれば基本的には楽勝です。
インスタンスを起動するときにユーザーデータを利用して復旧するようにしておきます。
リストア用のスクリプトを用意する
ユーザーデータの中から呼び出すスクリプトを用意します。手順は以下の通り。
- サービスの停止
- S3 バケットからオブジェクトのダウンロード
- データベースのリストア
- サービスの開始
mongorestore コマンドを使えばそのままスルッと復旧できます。
起動テンプレートにまとめる
スクリプトを仕込んだ AMI を作成して起動テンプレートの中にユーザーデータを仕込んでおきます。
先程のシェルスクリプトを呼び出すだけのものです。
まとめ
スポットインスタンスの中断によるデータロストを防ぐために中断通知イベントでデータのバックアップを行うように整備しました。
また、Fault Injection Simurator を使って中断通知の試験もしているので次に事が起きてもしっかり対応してくれるでしょう。
これだけのアクションと検証をサーバーレスですべて実現できるので最高です。
ひとつ課題としては、アップロードしたバックアップファイルを度のタイミングで消そうかな・・・。というところです。
データベースのリストア後に消しに行っても良いんですけど、リストアが失敗したときのことを考えると怖いかな。とも。
S3 のオブジェクトバージョニングを有効にして、インスタンスの復旧が失敗していたときは、削除マーカーを手動で消してリトライする。バージョニングファイルは1週間程度で完全削除する。これでいいかな?